Tahukah kamu kalau sebuah AI model pada dasarnya cuma sekumpulan file angka sampai kamu menghubungkannya ke internet? Di artikel ini, kita bakal bahas betapa mudahnya melakukan deploy open-source language model yang canggih dengan GPU acceleration! Bagian terbaiknya adalah, ini sepenuhnya serverless, siap untuk di-scale secara global, dan bisa dilakukan hanya dengan beberapa perintah di Google Cloud.
Kenapa Membangun Otak AI Kamu Sendiri?
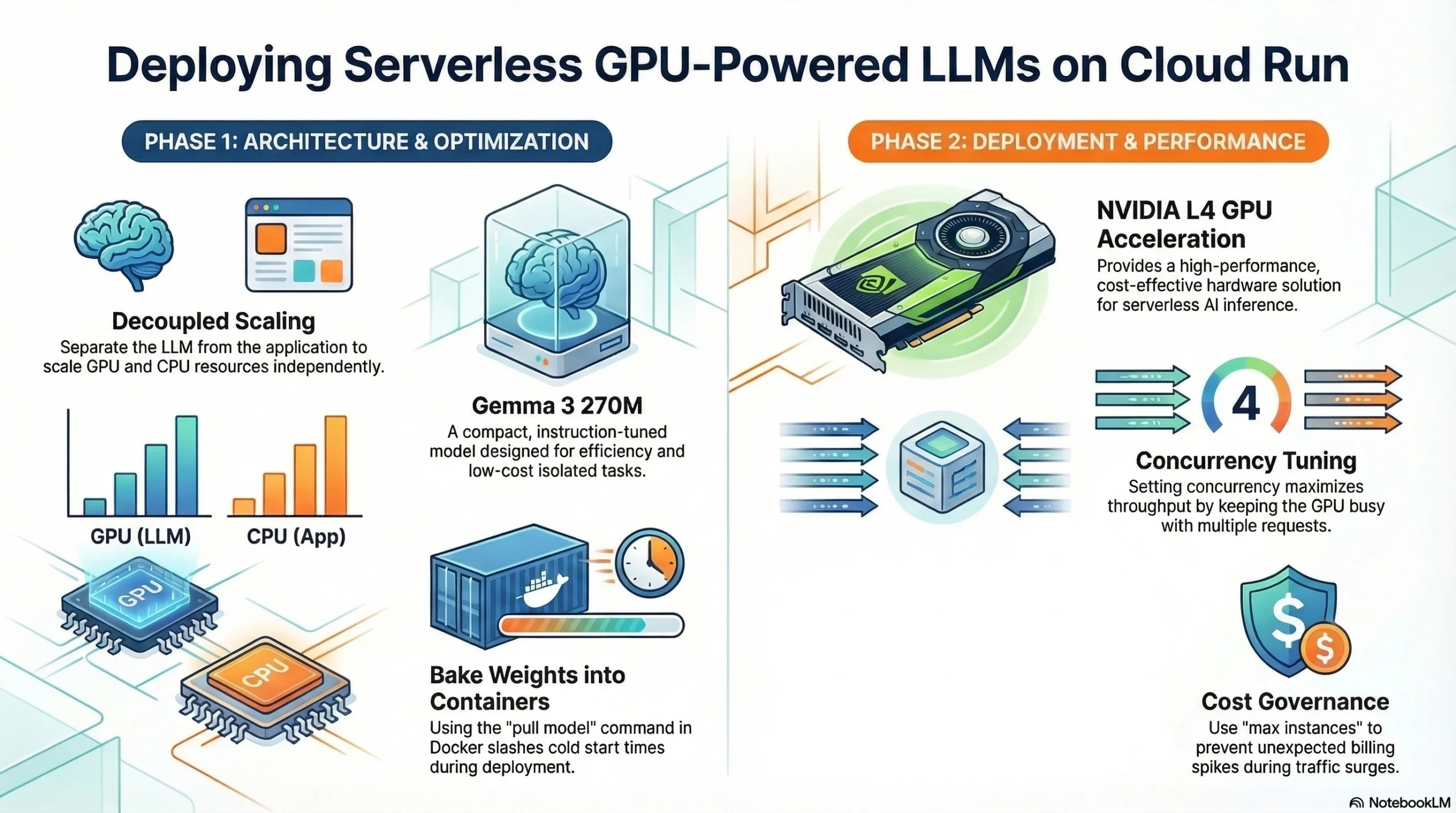
Kamu mungkin bertanya-tanya kenapa kita tidak pakai model yang sudah ada dan siap pakai saja untuk AI agents kita. Melakukan deploy Large Language Model (LLM) secara decoupled memungkinkan kamu untuk men-scale-nya secara mandiri dan melakukan fine-tune untuk tugas-tugas yang sangat spesifik. Misalnya, kamu bisa men-fine-tune sebuah model agar menjadi pemandu wisata kebun binatang spesialis yang bisa menjawab pertanyaan apa pun tentang hewan-hewan di sana! Karena model ini akan menggunakan GPU resources—yang sedikit lebih mahal dari CPU resources—men-scale komponen ini secara terpisah adalah langkah yang cerdas dan hemat biaya.
Kenalan dengan Tech Stack-nya: Gemma dan Ollama
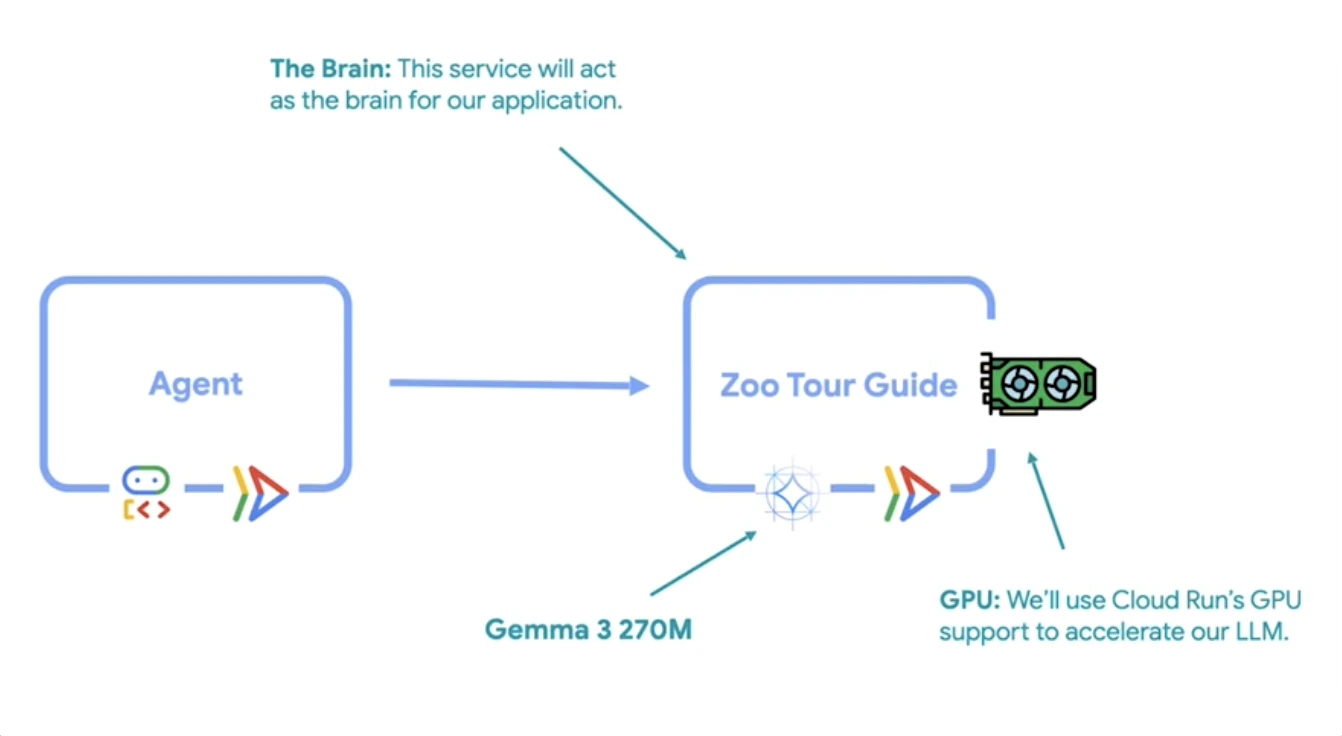
Sebagai “otak” untuk AI agent kita, kita akan menggunakan open-source model baru dari Google yang berukuran mungil: Gemma 3 270M. Model yang ringkas ini hanya memiliki 270 juta parameters, sudah instruction-tuned, hemat energi, dan memiliki fitur quantization yang production-ready. Hal ini membuatnya sangat cocok untuk menangani tugas-tugas terisolasi sambil menjaga biayamu tetap rendah! Untuk me-serve model ini dengan mudah, kita akan menggunakan LLM serving framework bernama Ollama.
Meracik Dockerfile yang Sempurna
Keajaiban sesungguhnya di balik deployment ini terjadi di dalam Dockerfile. Kita mulai dengan image resmi Ollama dan mengatur beberapa environment variables yang penting. Pertama, host variable dari Ollama memastikan service tersebut bisa menerima requests dari mana saja, bukan hanya dari mesin lokal kamu. Selanjutnya, keep alive pada Ollama adalah optimasi kunci yang memberi tahu sistem agar jangan pernah meng-unload model tersebut dari memory GPU, sehingga akan mempercepat semua requests berikutnya! Terakhir, perintah Run pull model akan memasukkan weights dari model langsung ke dalam container image kita, yang mana akan memangkas cold start times secara drastis saat ada instance baru yang menyala.
Berikut adalah contoh isi Dockerfile yang bisa kamu gunakan:
# Menggunakan base image resmi dari Ollama
FROM ollama/ollama:latest
# Konfigurasi environment variables agar bisa diakses dari luar dan tetap di memory GPU
ENV OLLAMA_HOST="0.0.0.0"
ENV OLLAMA_KEEP_ALIVE="-1"
# Menjalankan Ollama di background sejenak untuk mem-pull model Gemma ke dalam image
RUN nohup bash -c "ollama serve &" && sleep 5 && ollama pull gemma3:270mKeajaiban Deployment Satu Perintah
Nah, ini dia bagian serunya: melakukan deploy semuanya hanya dengan satu perintah! Saat kita menjalankan perintah gcloud run deploy, kita mengatur beberapa flags penting untuk meminta hardware dan mengontrol performa:
- Hardware: Kita meminta satu Nvidia L4 GPU, yang merupakan mesin super cepat dan hemat biaya untuk inference. Kita juga mengalokasikan 16 GB system memory dan 8 CPUs untuk mendukung GPU dan mengatur aliran data.
- Concurrency: Kita mengatur kenop performa ini ke angka 4, yang berarti setiap instance dari service kita akan menangani hingga empat requests di waktu yang bersamaan. Ini akan memaksimalkan throughput dan membuat GPU tetap sibuk!
- Cost Control: Kita membatasi maximum instances di angka 3 agar kita tidak kaget dengan tagihan yang tiba-tiba membengkak.
Jalankan perintah ajaib ini di terminalmu (pastikan kamu berada di directory yang sama dengan Dockerfile):
gcloud run deploy ai-agent-brain \
--source . \
--gpu=1 \
--gpu-type=nvidia-l4 \
--memory=16Gi \
--cpu=8 \
--concurrency=4 \
--max-instances=3 \
--allow-unauthenticated \
--region=us-central1Begitu kamu menekan enter, Google Cloud Build akan mengambil Dockerfile tersebut, mem-build image-nya, dan men-deploy-nya ke Cloud Run. Setelah sekitar lima menit untuk mengunduh model dan mem-provision GPU-nya, deployment selesai dan akan langsung memberikan sebuah live URL!
Apa Selanjutnya?
Selamat, kamu baru saja berhasil men-deploy open-source language model yang sangat powerful di sebuah platform serverless dengan dedicated GPU hardware! Sistem ini sudah siap untuk di-scale dan melayani requests dari mana saja di seluruh dunia. Namun, meskipun kita sudah membangun “otak” yang luar biasa, ia belum bisa mengobrol dengan siapa pun saat ini. Langkah selanjutnya dalam membangun sistem kita adalah menciptakan “wajah” dari aplikasi kita—sebuah ADK agent—dan menghubungkannya langsung ke backend bertenaga GPU yang baru ini!