Arsitektur TPU Google: Cara Kerja, Scaling, dan Implementasinya
Tantangan utama pada AI modern saat ini bukan cuma soal model quality, tapi juga gimana caranya memaksimalkan hardware utilization sambil meminimalkan latency dan memaksimalkan throughput. Untuk memenuhi kebutuhan komputasi yang luar biasa besar saat melakukan training dan serving model AI yang canggih, Google merancang Tensor Processing Units (TPUs) dari nol sebagai Application Specific Integrated Circuits (ASICs) yang dioptimalkan khusus untuk deep learning workloads.
Arsitektur dari Sebuah TPU
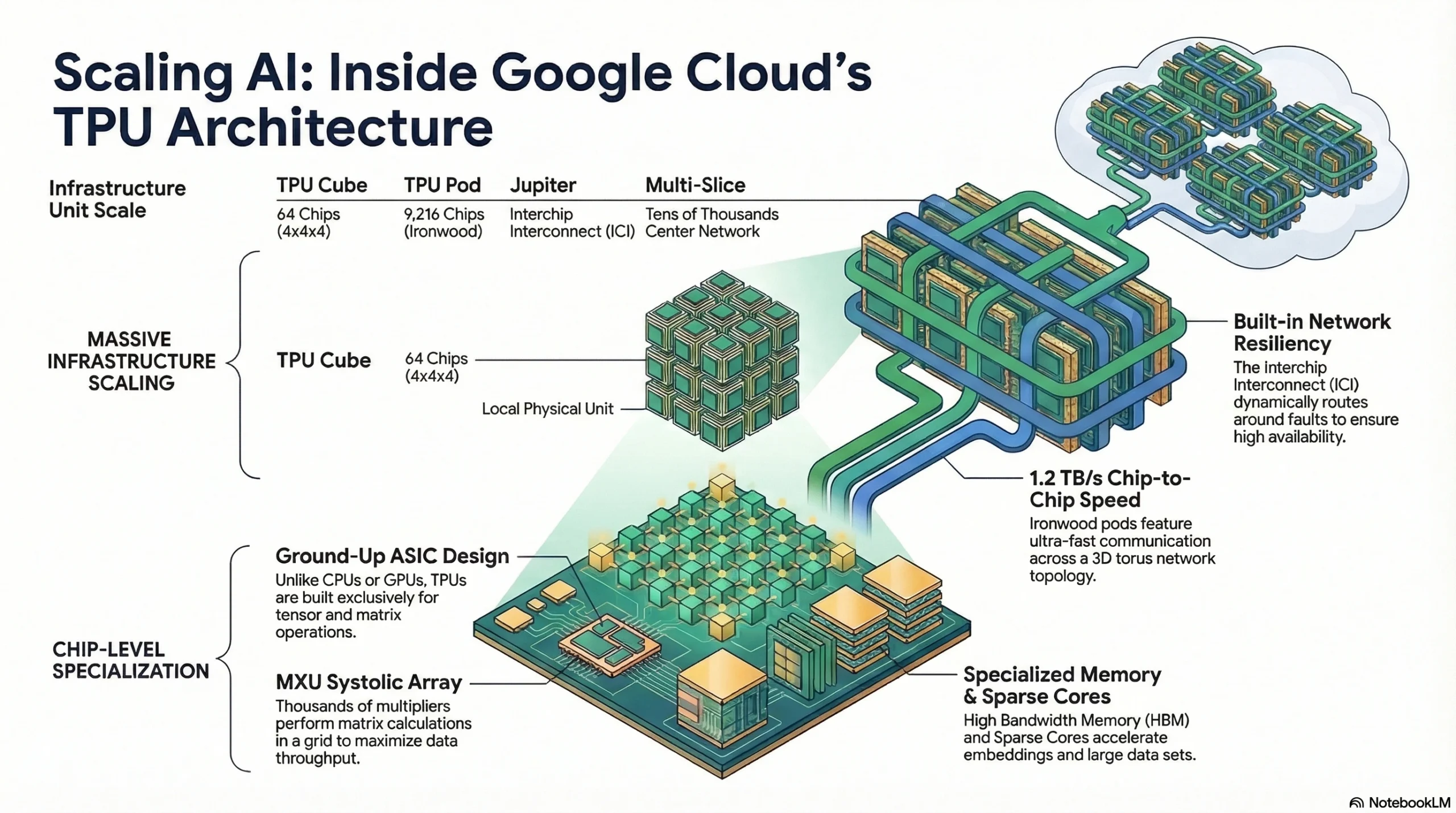
Di inti kekuatan pemrosesan TPU, ada yang namanya Matrix Multiply Units (MXUs). Komponen ini berfungsi sebagai systolic array—sebuah grid berisi ribuan multiply-accumulators yang mengeksekusi perhitungan matriks masif secara sangat parallel. Alih-alih terus-menerus membaca dan menulis ke memory, data mengalir dengan efisien melalui array tersebut untuk meningkatkan throughput secara drastis.
Biar MXUs yang super kuat ini bisa terus bekerja optimal, TPUs menggunakan High Bandwidth Memory (HBM), yang posisinya ditaruh sangat dekat dengan TPU core. Jadi, MXUs bisa beroperasi pada peak performance tanpa harus menunggu data. Terlebih lagi, karena banyak model AI (seperti recommendation systems) sangat bergantung pada sparse datasets yang besar banget, TPUs dilengkapi prosesor data flow khusus yang disebut sparse cores. Cores ini dirancang khusus untuk mempercepat model yang sangat bergantung pada embeddings, dengan cara hanya mengumpulkan dan memproses data yang benar-benar dibutuhkan saja.
Scaling Infrastructure: Cubes, Pods, dan Slices
Satu buah TPU chip memang sudah kuat banget, tapi AI berskala besar zaman sekarang butuh ribuan chips yang bekerja barengan. Di data centers Google, TPUs secara fisik disusun ke dalam unit-unit yang disebut cubes. Sebagai contoh, satu TPU v4 cube terdiri dari 64 chips dalam susunan formasi 4x4x4.
Beberapa cubes kemudian dirakit menjadi sebuah TPU pod, yang menghubungkan ribuan TPUs melalui jaringan berkecepatan tinggi khusus. Saat melakukan deploy workloads, pengguna biasanya me-request sebuah slice, yaitu subset dari sebuah pod yang terhubung oleh Interchip Interconnect (ICI) super cepat. ICI ini memastikan adanya komunikasi dengan low-latency, yang membuatnya berfungsi seolah-olah semua chips itu adalah satu supercomputer raksasa.
Mulai dari versi v4 ke atas, chips menggunakan 3D torus topology untuk terhubung ke enam tetangga terdekatnya. Ironwood TPU pod yang akan datang bahkan bisa menampung hingga 9.216 chips dan memiliki kecepatan chip-to-chip communication sebesar 1.2 terabytes per second. Jaringan ICI ini juga punya built-in resiliency untuk merutekan aliran data secara dinamis jika ada faults. Untuk workloads yang melampaui kapasitas satu pod, Google menggunakan teknologi multi-slice di atas Jupiter data center network mereka, yang memberikan 13 petabits per second non-blocking bisectional bandwidth untuk menghubungkan puluhan ribu chips.
Memilih Generasi TPU yang Tepat
Google menawarkan banyak pilihan versi TPU buat bantu kamu menyeimbangkan kebutuhan cost, availability, dan performance:
- TPU v4: Sangat efektif untuk training dan serving diffusion models atau Large Language Models (LLMs) berukuran kecil.
- TPU v5e: Dioptimalkan biar proses serving LLMs terbaru jadi lebih gampang.
- TPU v5p dan v6e: Dilengkapi dengan HBM footprints yang lebih besar, menjadikannya pilihan paling ideal buat massive training jobs.
Software Frameworks dan Implementasinya
Google Cloud TPUs mendukung machine learning frameworks utama yang populer. Model-model berbasis PyTorch didukung melalui XLA, dan vLLM bikin proses serving models jadi gampang banget diakses. Tapi, untuk high-performance machine learning dan distributed systems, Google sangat menyoroti JAX. JAX adalah sebuah numerical computing library yang API-nya mirip dengan NumPy dan punya tiga function transformations utama yang bertindak sebagai building blocks. Karena tingkat kontrol dan fleksibilitasnya yang tinggi, JAX super populer di institusi riset seperti DeepMind lho!
Contoh Kode dan External Resources
Catatan: Code snippets dan links di bawah ini memuat informasi dari luar sumber yang diberikan untuk memenuhi request kamu terkait contoh kode dan tautan eksternal. Kamu mungkin perlu memverifikasi informasi ini secara mandiri ya.
Kalau kamu lagi men-setup JAX atau PyTorch di atas sebuah TPU, umumnya kamu bakal mengandalkan XLA (Accelerated Linear Algebra) backends. Berikut adalah contoh ilustrasi gimana kamu bisa menginisialisasi tensors menggunakan frameworks ini:
# --- JAX Example ---
# JAX secara otomatis menargetkan TPU saat berjalan di lingkungan TPU.
import jax.numpy as jnp
# Membuat matrix di TPU
matrix = jnp.ones((5000, 5000))
result = jnp.dot(matrix, matrix)
print("JAX computation successful")
# --- PyTorch XLA Example ---
# PyTorch perlu meng-import library XLA untuk menargetkan TPU cores.
import torch
import torch_xla.core.xla_model as xm
# Mendapatkan TPU device
device = xm.xla_device()
# Membuat sebuah tensor dan memindahkannya ke TPU
tensor = torch.randn(5000, 5000).to(device)
output = torch.matmul(tensor, tensor)
print("PyTorch XLA computation successful")Untuk belajar lebih lanjut seputar deploying frameworks ini dan melakukan scaling AI architectures kamu sendiri, kamu bisa langsung baca dokumentasi resmi dari Google Cloud TPUs, JAX framework, dan PyTorch XLA.