Large Language Models (LLM) punya satu keterbatasan mendasar: mereka “terjebak di masa lalu”. LLM hanya tahu informasi sampai batas waktu pelatihan mereka (training cutoff date) dan sama sekali tidak tahu tentang peristiwa terkini atau data pribadi milikmu, seperti internal wikis atau codebases. Untuk mengatasi ini, developer harus mengandalkan context injection—sebuah metode untuk memasukkan data yang tepat ke dalam model di waktu yang tepat pula.
Saat ini, ada dua arsitektur utama untuk melakukan context injection: Retrieval-Augmented Generation (RAG) dan Long Context.
Dua Kontestan Utama: RAG vs. Long Context
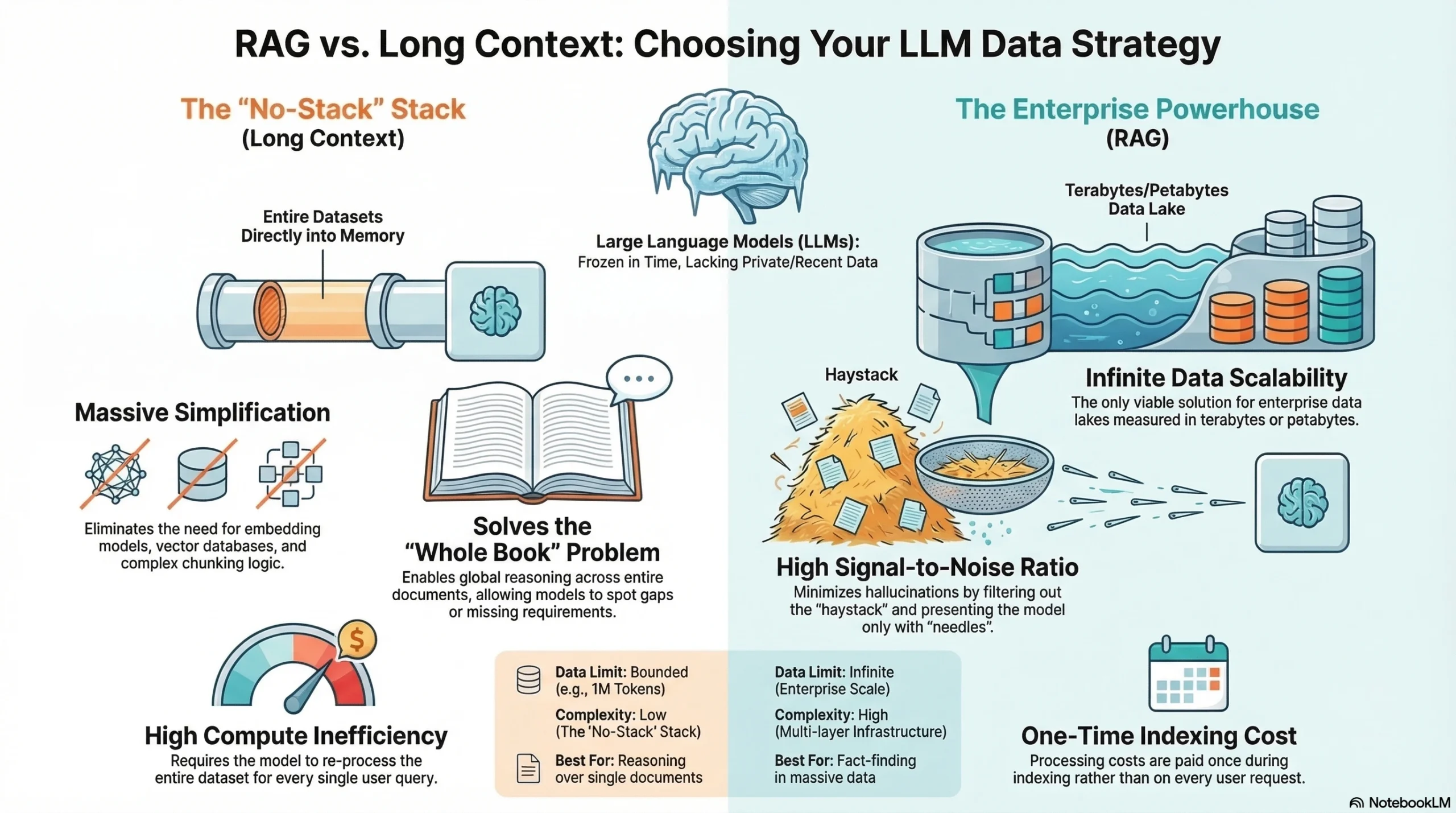
Retrieval-Augmented Generation (RAG) dianggap sebagai pendekatan berbasis engineering. Dalam sistem RAG, dokumen sumber (seperti PDF, file kode, atau buku) dipecah menjadi bagian-bagian kecil yang disebut chunks. Chunks ini kemudian melewati embedding model untuk diubah menjadi vectors dan disimpan dalam vector database khusus. Saat pengguna memberikan pertanyaan (query), sistem melakukan semantic search untuk mengambil chunks dokumen yang paling relevan dan memasukkannya ke dalam context window milik LLM bersamaan dengan user prompt.
Long Context, di sisi lain, adalah solusi “model native” yang menggunakan pendekatan brute-force. Alih-alih mengandalkan database dan embedding model, kamu cukup memasukkan seluruh set dokumen langsung ke dalam context window LLM dan membiarkan mekanisme attention milik model tersebut menemukan jawabannya sendiri. Jika dulu LLM punya context window yang kecil (sekitar 4.000 tokens), model saat ini sanggup menangani lebih dari satu juta tokens—cukup untuk menampung seluruh seri Lord of the Rings dan The Hobbit dalam satu prompt.
Alasan Memilih Long Context: Kenapa RAG Mungkin Tidak Lagi Dibutuhkan?
Dengan context window raksasa yang tersedia sekarang, memasukkan data secara langsung menawarkan beberapa keuntungan dibanding RAG:
Menyederhanakan Infrastruktur
Sistem RAG untuk tahap produksi itu cukup berat. Kamu butuh chunking strategy, embedding model, vector database, reranker, dan sinkronisasi terus-menerus dengan data sumber. Long context mengandalkan konsep “no stack stack”, membuang kebutuhan akan database dan logika retrieval, sehingga arsitekturnya jauh lebih simpel.
Menghindari “Retrieval Lottery”
RAG dibangun di atas probabilistic semantic searches. Jika langkah retrieval gagal menemukan dokumen yang relevan di vector database—fenomena yang disebut silent failure—LLM tidak akan pernah melihat jawabannya meskipun data tersebut sebenarnya ada. Long context menghapus langkah retrieval ini, memastikan model melihat segalanya.
Menyelesaikan Masalah “Satu Buku Utuh”
RAG sering kesulitan jika jawaban membutuhkan pemahaman tentang apa yang “hilang” atau tidak ada. Contohnya, jika kamu minta LLM membandingkan dokumen kebutuhan (requirements) dengan release notes untuk mencari celah keamanan yang terlewat, RAG hanya akan mengambil potongan teks terisolasi tentang keamanan, tapi tidak bisa melihat “celah” di antaranya. Long context menyelesaikan ini dengan memasukkan kedua dokumen utuh, sehingga model bisa melihat gambaran besarnya.
Alasan Memilih RAG: Kenapa Vector Database Tetap Bertahan?
Meski long context terlihat simpel, RAG masih jauh dari kata “mati”. Ada tiga alasan utama mengapa RAG tetap krusial:
Pajak Membaca Ulang (Rereading Tax)
Long context sangat tidak efisien dari sisi komputasi. Jika kamu memasukkan manual setebal 500 halaman (sekitar 250.000 tokens), model harus memproses seluruh manual tersebut setiap kali ada pertanyaan baru. Sedangkan RAG hanya membayar biaya pemrosesan berat itu sekali saat fase indexing. Untuk data dinamis yang sering berubah, long context memaksamu membayar “pajak pemrosesan” yang besar di setiap permintaan.
Masalah Jarum dalam Tumpukan Jerami (Needle in the Haystack)
Penelitian menunjukkan bahwa saat context window membesar (misal: 500.000 tokens), fokus atau attention model bisa menjadi lemah. Jika jawaban terkubur di tengah dokumen setebal 2.000 halaman, model long context mungkin gagal menemukannya atau malah berhalusinasi. RAG membuang tumpukan jerami tersebut dan hanya memberikan “jarum” (chunks) yang paling relevan kepada model.
Dataset Tak Terbatas
Meskipun satu juta tokens itu besar, enterprise data lakes seringkali berukuran terabytes atau petabytes. Context window hanyalah setetes air di dalam ember jika dibandingkan dengan skala tersebut. Artinya, lapisan retrieval mutlak diperlukan untuk menyaring dataset perusahaan yang masif agar muat ke dalam LLM.
Kesimpulan: Mana yang Harus Kamu Pilih?
Keputusan antara RAG dan long context sepenuhnya bergantung pada skala datamu dan kasus penggunaannya (use case).
Jika kamu berurusan dengan dataset yang terbatas dan butuh penalaran menyeluruh (global reasoning)—seperti merangkum satu buku utuh atau menganalisis kontrak hukum tertentu—Long Context adalah pendekatan yang disarankan karena menyederhanakan teknologi dan meningkatkan kualitas penalaran.
Namun, jika kamu harus menavigasi dataset perusahaan yang sangat besar dan tak terbatas, Vector Database dan RAG tetap menjadi satu-satunya solusi yang layak untuk arsitekturmu.